RuLib
Программное обеспечение для создания и сопровождения распределенных библиотек.
Дадим краткое описание этапов создания и сопровождения пиринговой библиотеки:
1. Поиск файлов для библиотеки.
2. Проверка на повтор (одинаковые документы нам не нужны)
3. Автоматическая или ручная идентификация файлов, т.е. присваивание им авторского названия.
4. Создание и ведение тематических каталогов, организация полнотекстового поиска документов.
Введем понятие единицы хранения в нашей библиотеке. Такой единицей будем считать "Электронный документ".
Определение: электронный документ это файл или множество файлов, которые сохранены в папке с авторским названием документа.
Например:
"\DELPHI 2005. РАЗРАБОТКА ПРИЛОЖЕНИЙ ДЛЯ БАЗ ДАННЫХ И ИНТЕРНЕТА. ВАЛЕРИЙ ФАРОНОВ"
Это папка с названием книги, а в ней находятся файлы: 00000009.djvu (сама книга), info.txt (краткая информация о книге) и cod.rar (исходные тексты программ, которые есть в книге). Такой подход будет несколько необычен для маленьких библиотек, но абсолютно универсален, для больших хранилищ документов. Т.к. понятие папки и файла существует во всех файловых системах, то библиотека становится универсально переносимой на любую современную файловую систему, поддерживающую длинные имена файлов. Для манипуляций с библиотекой достаточно простых файловых менеджеров. Таким образом, библиотека будет представлять из себя несколько "Корневых папок" в которых будут храниться файлы документов (книг, журналов, статей), каждый в своей папке. Приведем самый простой пример: Корневые папки -
"D:\Библиотека\Книги "
"D:\Библиотека\Журналы"
"D:\Библиотека\Статьи"
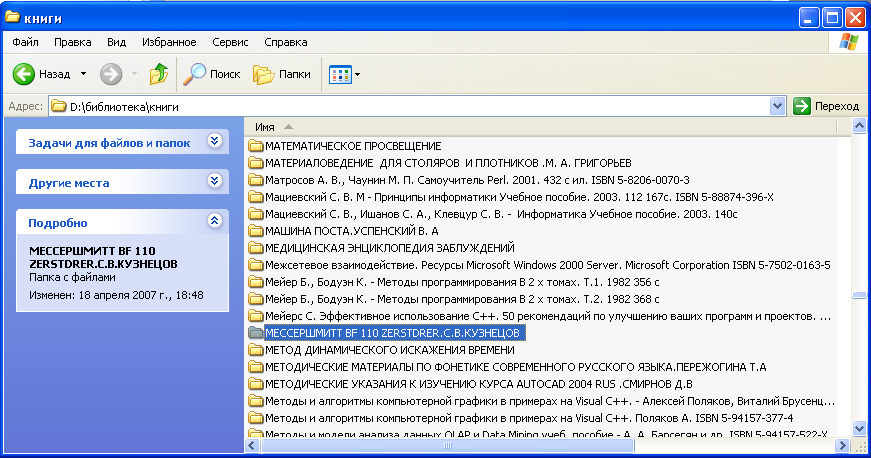
Рис. Корневая папка "Книги"
На самом деле конечно корневых папок обычно больше, но мое глубокое убеждение, что чем их больше, тем хуже. Т.к. при сортировке неизвестных документов вам потребуется давать им не только авторское название, что в некоторых случаях поддается автоматизации, но еще и сортировать документы по иерархии ваших корневых папок. И чем проще такая иерархия, тем и сортировка проще. Желание рассортировать книги по тематическим разделам (Информатики, Математика, Медицина и т. д.) должны решаться совершенно другими способами и эти способы должны быть отделены от способа хранения документов. Тем более что, некоторые книги по содержанию могут быть на стыке наук, и вы их не сможете одновременно поместить сразу в нескольких разделах без их физического дублирования, что в принципе не желательно.
Поиск файлов для библиотеки.
Решим главный вопрос: "Откуда взять файлы, которые будут хранится в нашей библиотеке?". Обычно бесплатный и самый распространенный источник это открытые спутниковые потоки. Десятки тысяч людей, пользователей спутникового Интернета, используя спутниковый канал передачи данных, каждый день выкачивают тысячи книг, журналов и много еще чего. Так создаются цифровые открытые спутниковые потоки. Значит, если у вас есть набор или несколько наборов спутникового Интернета (антенна-тарелка с конвертером и карта приема и обработки спутникового сигнала), вы можете совершенного бесплатно приобщиться к этим открытым спутниковым потокам. С помощью специальных программ (обычно это skynet), вычленяют из спутникового потока нужные файлы (книги и журналы) и сохраняют их на жестких дисках.
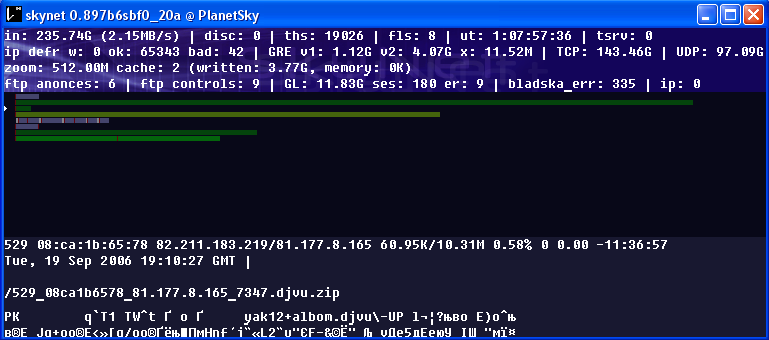
Рис. Skynet в работе.
О работе спутникового Интернета можно почитать здесь http://spacelib.narod.ru/intro.html .
При выделении из спутникового потока файлов с электронными документами, имя файла, как правило установить не удается. Файлы получают имена, которые не отражают содержимое документа, но тип файла, а значит и его расширение skynet назначает правильно. В сети 90% всех книг и журналов представлены в форматах: PDF и DJVU. Такие форматы как, doc, rtf, txt менее популярны, к тому же doc еще и опасен. При правильных настройках в файле regex.txt файлы формата PDF и DJVU будут сохраняться на диске в папке "..\skynet\ok" с расширениями *.PDF ,*.DJVU или *.PDF.rar , *.PDF.zip, *.PDF.z, *.DJVU.rar, *.DJVU.zip, *.DJVU.z и т.д. Я обычно переношу их в отдельный каталог "\skynet\архивы_книг". Когда в нем накопилось "много" файлов, начинаем процесс обработки. Для начала надо распаковать архивы. Это делается обычно "ручками" или можете использовать программу ProcessingArchive. (Подробнее).
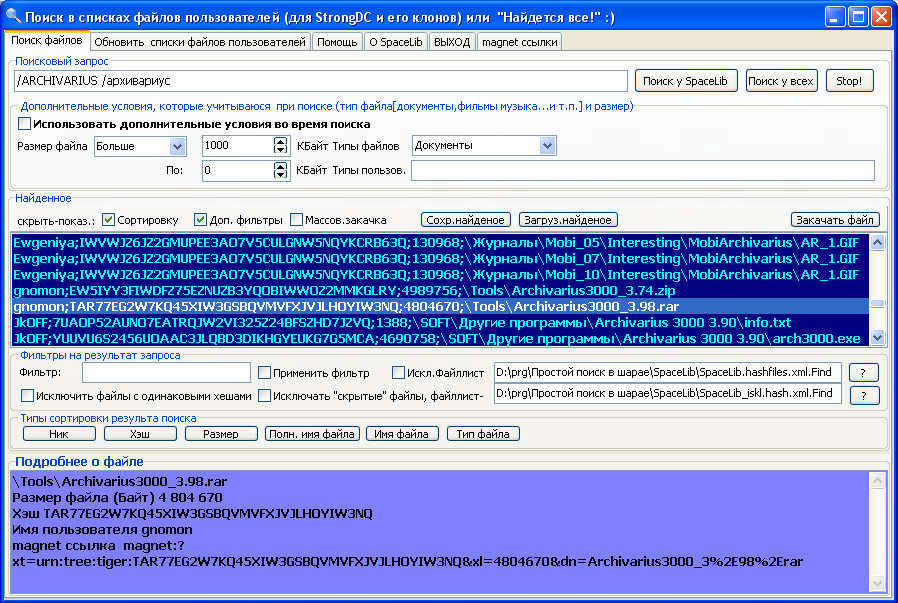
Другим не мене важным "условно-бесплатным" источником для нашей библиотеки может стать локальная пиринговая сеть вашего провайдера. Обычно трафик в такой сети бесплатен, качай сколько хочешь! Платить нужно только за подключение и абонентскую плату (обычно не более 100 руб. в месяц без включенного внешнего трафика). Сейчас в России наиболее распространены DC (DirectConnect) пиринговые сети. Программное обеспечение для функционирования: Хабы (YnHub, PtokaX, VerliHub, LinuxDC++) и Клиенты (StrongDC++ и его клоны) бесплатны и русифицированы. Клиенты, как правило, имеют открытые исходные коды, что облегчает их адаптацию под местную специфику.
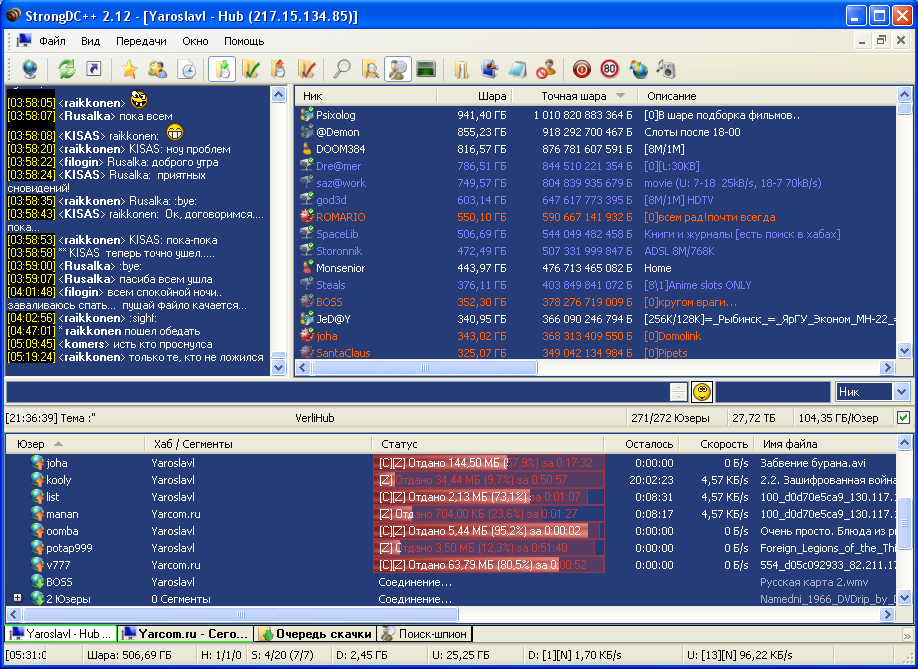
Рис. StrongDC++ - один из популярных клиентов.
Если в вашей пиринговой сети сотни или тысячи пользователей, то для поиска книг и журналов нет необходимости открывать списки файлов каждого и искать документы для закачки. Проще воспользоваться SSearch.exe - программой офф-лайн поиска файлов в p2p-сетях на основе StrongDC и ее функцией "Массовая закачка". Т.е. сначала вы делаете поиск всех книг и журналов в вашей пиринговой сети, с помощью фильтров удаляете не нужные документы (например: всякие доки к популярным программам). Далее полученный список сохраняете в файле Q.xml - имя по умолчанию. Файл будет сохранен в папку с SSearch. И наконец ручками в стандартном Блокноте вставляете содержимое Q.xml в файл "ххх\Settings\Queue.xml" (где ххх означает папка с вашим StrongDC.exe или у кого что). Не забудьте сделать копию Queue.xml для страховки!
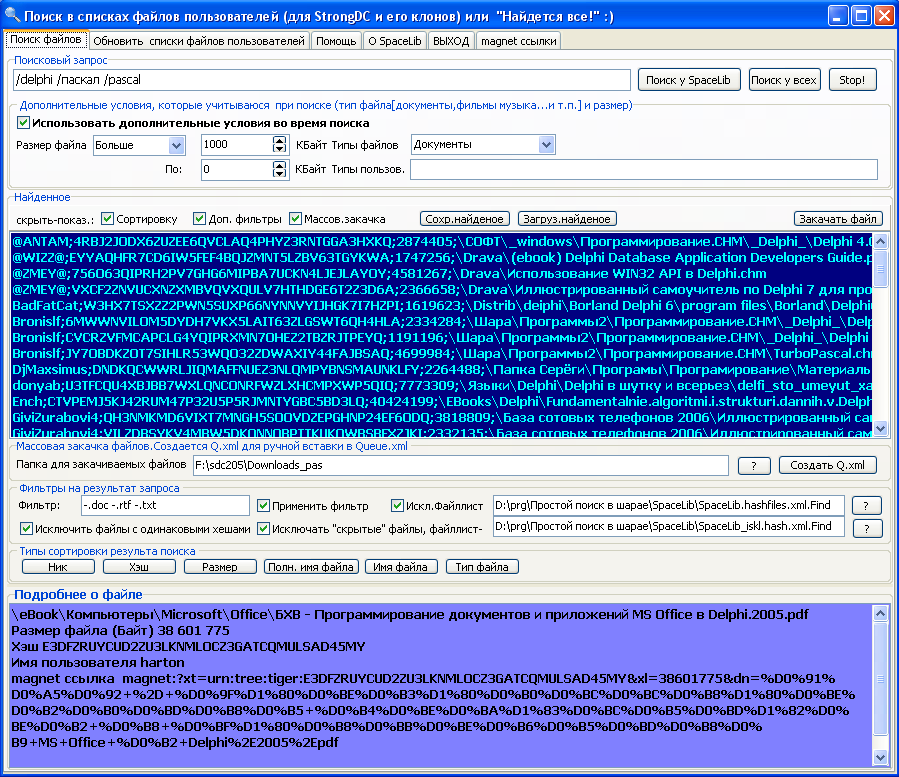
Рис. Подготовка к закачке с помощью SSearch документов по Паскалю-Delphi.
Запускаете вновь StrongDC и он начнёт "массовую закачку". Для ускорения процесса, нужно выбрать всех пользователей хаба и щелкнув правой кнопкой мышки по выделенному списку, выбрать пункт меню "Сравнить очередь". Начнется закачка списков файлов у пользователей. Каждый скаченный список будет проверен, и если в нем есть нужный вам файл, именно у этого пользователя Стронг начнет его скачивать. Если таких пользователей будет несколько, Стронг будет скачивать файл у них всех одновременно, многократно ускоряя закачку.
Проверка на повтор (одинаковые документы нам не нужны!).
Скачав или вычленив из спутниковых потоков тысячи файлов, нужно убедиться, что среди них нет одинаковых файлов. Воспользуемся программой DelDubl. Она удаляет повторяющиеся файлы в заданном каталоге, умеет работать, как по таймеру, так и в ручном режиме.
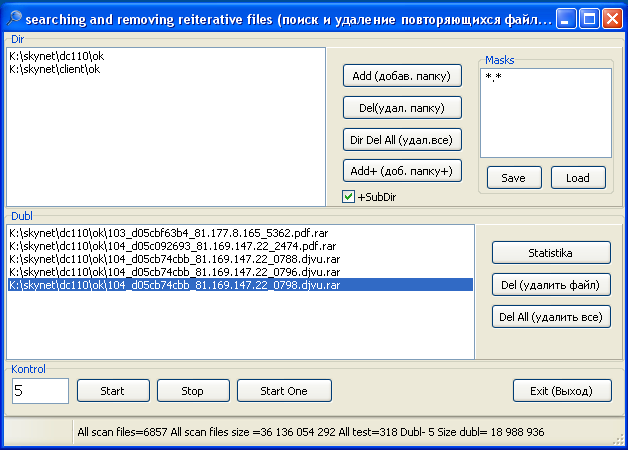
Рис. Работа программы DelDubl. Примерно 10-20 процентов файлов из спутникового потока повторяются.
После проверки на дубли, запускаем программу SpaceLib и ищем в файлах кандидатах в библиотеку те, которые в библиотеке уже есть. Найденные файлы удаляем.
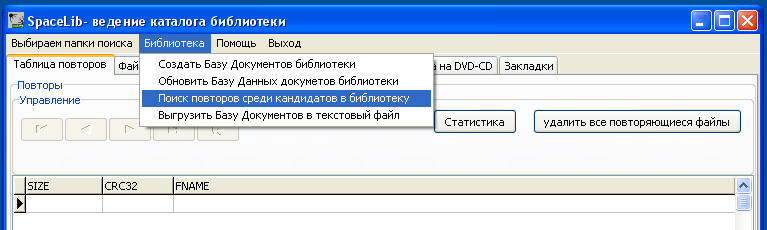
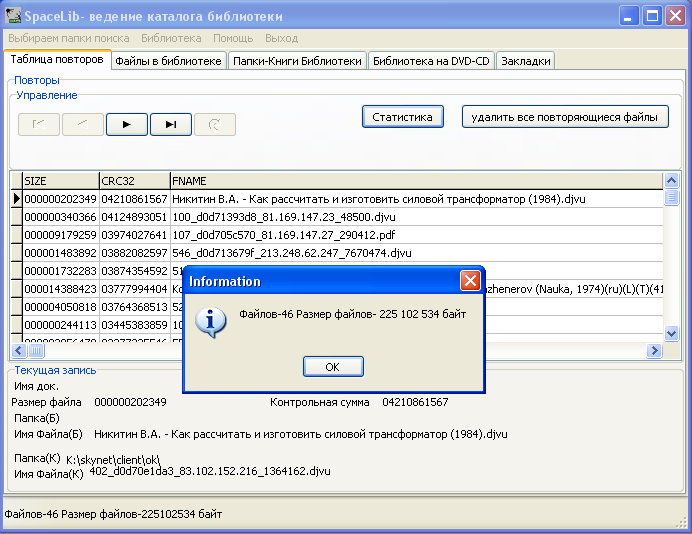
Рис. С помощью SpaceLib ищем файлы которые уже есть в вашей библиотеке и удаляем их.
Автоматическая или ручная идентификация файлов, т.е. присваивание им авторского названия.
Теперь попытаемся идентифицировать те файлы, которые описаны в базе идентификации, но их еще нет в вашей библиотеке. Запустив FindNameDocs, указываем, где хранится файлы базы идентификации и куда переносить найденные в ней файлы. В FindNameDocs идентификация производится по контрольной сумме и длине файла, но существует вторая версия данной программы ED2K_FNDocs, которая использует MD5 хеш или хеш пирингового клиента "Осел".
Рис. FindNameDocs идентифицирует неизвестные файлы.
Совершенно очевидно, что не все файлы будут описаны в Базе идентификации, а это значит, что часть документов нужно будет сортировать "руками". Т.е. открывать документ оценивать его значимость и если он вам нужен, то давать ему авторское имя, иначе удалять. Это самая трудоемкая часть работ для хранителя библиотеки! Однако, если есть сообщество людей, которое будет делиться друг с другом своей УНИКАЛЬНОЙ частью базы идентификации, т.е. информацией о документах которые они отсортировали сами "руками", то не все так плохо. Для ручной сортировки используем программу AllDocView. Она предназначена для быстрой сортировки документов и использует установленные у вас ActivX объекты для показа выбранных документов. Контейнером для таких объектов является Internet Explorer. Это значит, что для корректной работы AllDocView он должен быть установлен в системе. Такое решение позволяет сортировать любые документы, которое в состояние отображаться в вашем Internet Explorer-е.
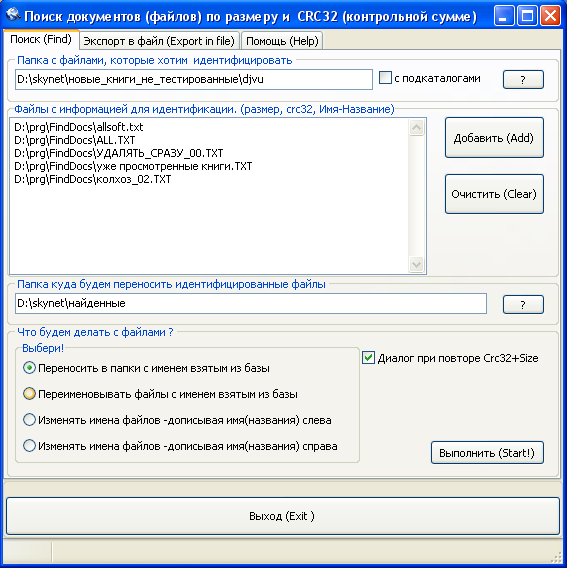
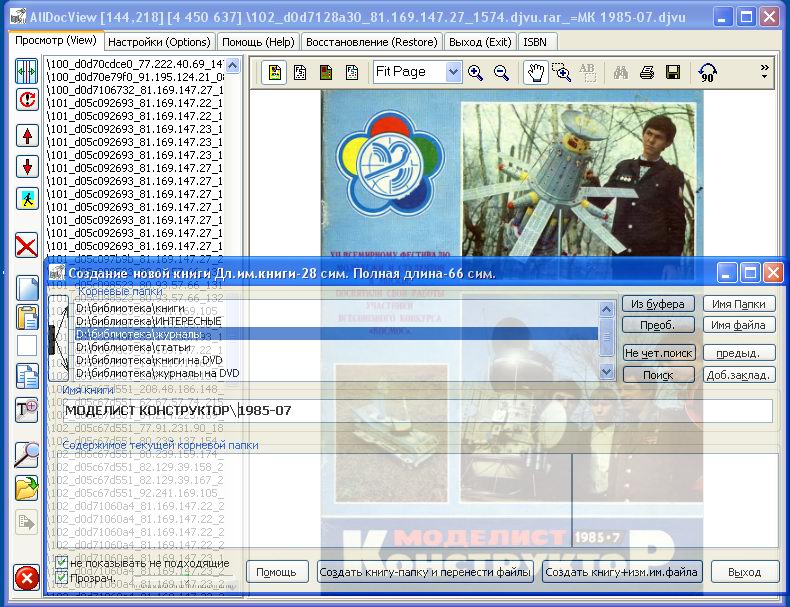
Рис. Ручная сортировка документов с помощью AllDocView
Процесс сортировки лучше разбить на два прохода. В первом вы удаляете все ненужное (Shift и стрелка вправо - переход к следующему документу, Shift и Del - "удаление" документа). Оцениваете объем оставленного к ручной сортировке материала. А уже во втором проходе начинаете переносить файлы документов в папки с осмысленными названиями, т.е. по сути создаете свою библиотеку документов.
Перед вызовом диалога "Новая книга" я захватываю в буфер обмена название книги из документа, если он конечно же содержит текст, а не изображение текста. Далее я нажимаю клавишу "Открыть окно "Новая книга" с текстом из буфера обмена". Текст из буфера обмена попадает в поле "Имя книги" и если оно вас устраивает, выбирайте корневую папку библиотеки (клавиши от F1 до F7 зарезервированы для быстрого выбора из списка). Нажав Enter вы перенесете текущий файл в "новую папку" с названием из поля "Имя книги". Как я уже говорил не всегда документ содержит текст. Очень часто присутствуют только изображения страниц или файл защищен. По этому я всегда стараюсь использовать "ABBYY Screenshot Reader". После того, как я с помощью мышки выделю прямоугольник с текстом, "ABBYY Screenshot Reader" его распознает, поместит в буфер обмена и подаст звуковой сигнал. Теперь можно нажимать клавишу "Открыть окно "Новая книга" с текстом из буфера обмена". Дале выбирайте корневую папку и переносите файл в папку с именем из поля "Имя книги".Как всегда в бочке с дегтем можно найти ложечку меда :) . Для этого написана и активно тестируется FindISBN - программа для полуавтоматического поиска названий книг. Она с помощью сторонних программ извлекает из документов текстовый слой и ищет в нем уникальный код книги - ISBN. По этому коду определяется авторское название книги. Программа использует или собственную базу названий или обращается к онлайновым каталогам. Если текстового слоя нет в документе, FindISBN преобразует несколько страниц документа в изображения и просит программу CuneiForm распознать их т.е. превратить в текст. Программа создает по ходу работы файлы сателиты (*.info,*.txt,*.isbn,*.NameBook, где *-имя файла книги у которой ищется название). Если все прошло удачно, то в файле *.NameBook хранится название(я) книги, которое может быть использовано программой AllDocView. Жмем на специальную иконку и получаем готовое название книги. К сожалению, практика показала, что полностью автоматизировать такой процесс не возможно. Обязательно возникают ошибки в распознавании ISBN или самих ISBN в книге может быть найдено несколько, да и онлайновые каталоги выдают множество вариантов названия для одной и той же книги. В книгах выпущенных до середины 80-ых ISBN вообще отсутствует.
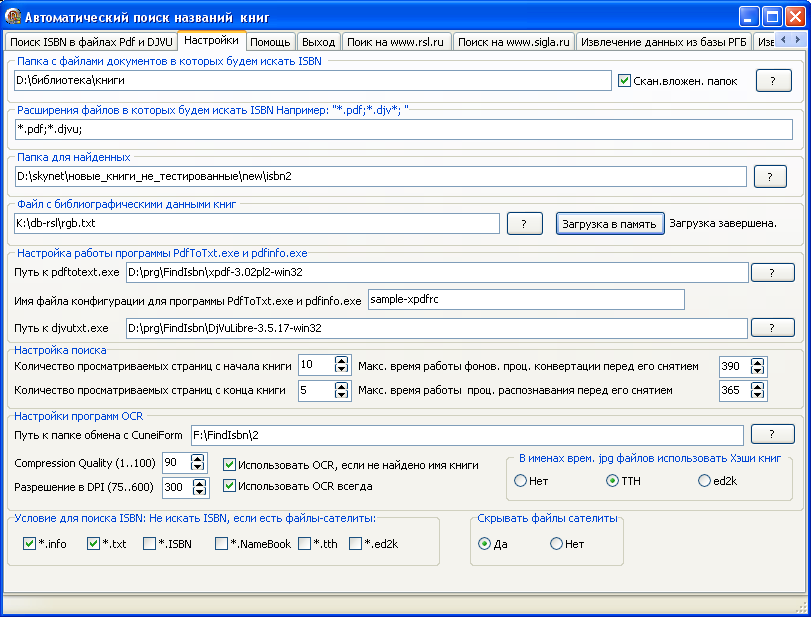
Рис. Настройки программы FindISBN .
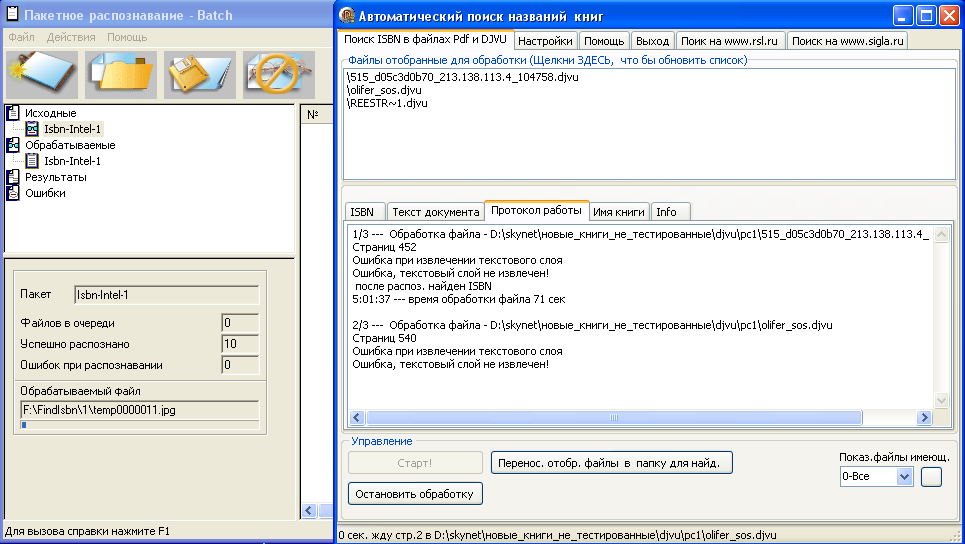
Рис. Работа программы FindISBN по поиску названий книг.
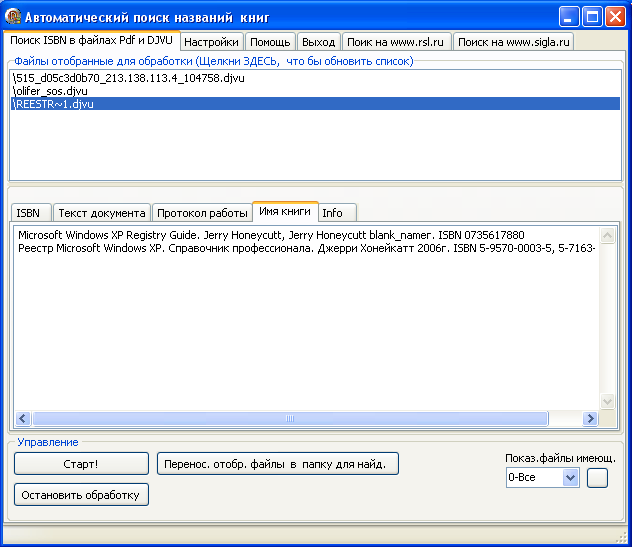
Рис. FindISBN нашла в файле REESTR~1.djvu сразу два ISBN, а значит и 2 названия книги.
FindISBN очень ресурсоемка, на поиск названия одной книги, если нет текстового слоя в документе, обычно уходит 1-3 минуты, при анализе 5 страниц с начала документа и 3 страниц с конца.
После того, как все документы получили свои названия, запускаем программу ведения каталога библиотеки - SpaceLib. Она просканирует библиотеку, найдет новые документы и информацию о них занесет в свою базу данных. SpaceLib легко ищет нужные вам документы, понимает расширенный язык запросов (почти как в поисковых системах),
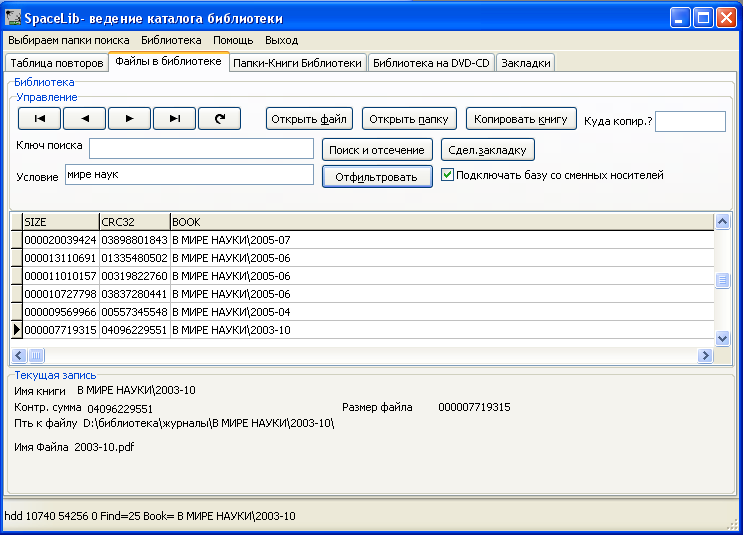
Рис. Используем SpaceLib для поиска журнала "В мире науки"
Создание и ведение тематических каталогов, организация полнотекстового поиска документов.
В создания и ведение тематических каталогов SpaceLib опирается на механизм закладок на документы. Закладки можно создавать, как во время сортировки документов в программе AllDocView, так и в SpaceLib. Файлы с закладками это простые текстовые файлы, имеющие расширение ".bms". Что бы программа строку из файла посчитала закладкой, она должна иметь определенный формат (контрольная_сумма_файла;размер_файла; Далее_все_что_угодно). "//" - явное указание строки с комментариями. Файлы *.bms можно рассматривать, как информационные поля ваших интересов по определенным темам, в которые вкраплены ссылки на документы.
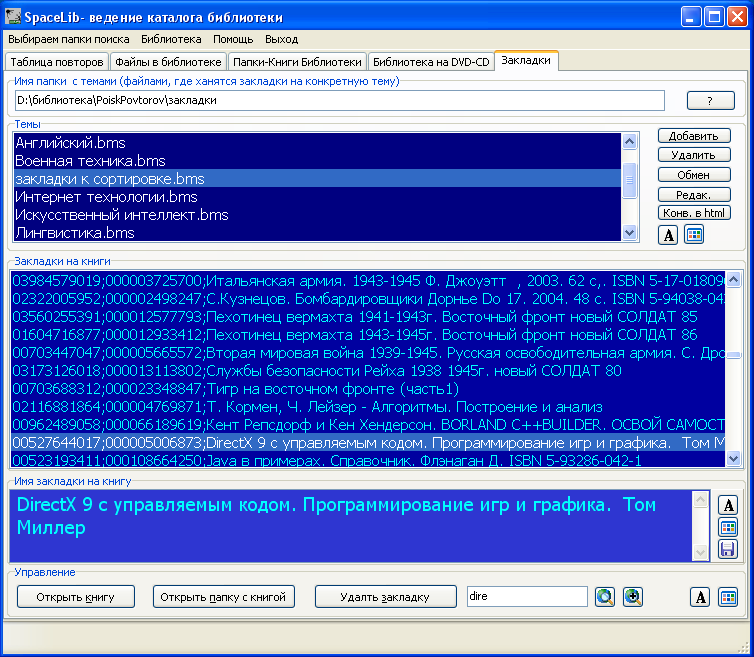
Рис. В еще не отсортированных закладках находим книгу по нужной теме.
Сами файлы *.bms можно размещать в дерево папок, тем самым, создавая тематический каталог любой сложности. Т.к. закладка прямо не указывает на файл документа, а только на его "уникальный маркер - хэш", то деревом папок с файлами закладок можно обмениваться. Их легко конвертировать в html для размещения на вашем сайте или страничке форума. Вместо контрольной суммы и длины файла в html записывается магнет ссылка. Если на такой магнет ссылке щелкнуть мышью, то браузер отдаст приказ пиринговому клиенту начать скачку файла. Здесь вы можете посмотреть тестовую страничку с магнет - ссылками.
Для того чтобы организовать полнотекстовый персональный поиск в библиотеке можно воспользоваться следующими бесплатными программами:
Персональный поисковик Яндекса - это программа осуществляющая поиск по файлам с учётом морфологии русского языка (страница загрузки http://desktop.yandex.ru)
Google Desktop - выполняет поиск в библиотеке так же легко, как и веб-поиск с помощью Google. (страница загрузки http://desktop.google.com)
Оба поисковика поддерживают формат djvu через установку плагинов.
Из коммерческих версий можно посмотреть на Архивариус 3000 (страница загрузки полнофункционально ознакомительной версии на 30 дней http://www.likasoft.com/ru/document-search/index.shtml).
Рис . Пример поиска Архивариусом версия 3.93. Архивариус имеет существенное ограничение - размер одного индекса не может быть больше 1.5 Гбайт.
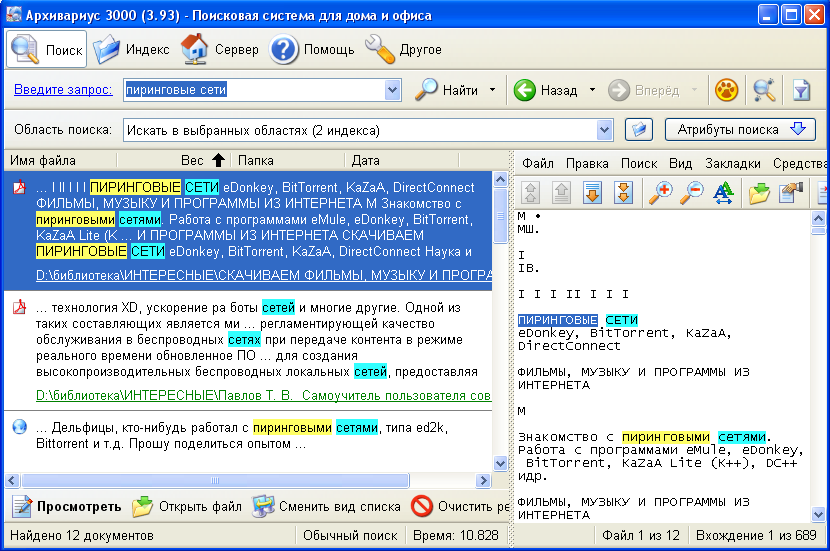
Архивариус 3000 умеет индексировать текстовый слой djvu, если он есть, но главное имеет встроенный Web сервер, который включается одним кликом мыши. Web сервер "садится" на указанный вами порт и полнотекстовый поиск по вашей библиотеке становится доступным из сети. Масштабируемость такого решения не высока - размер одного индексного файла не может быть больше 1.5 Гб, однако для небольшой локальной сети вполне приемлема. Для того что бы, исключить доступ к вашему Web серверу из внешней сети, необходимо правильно настроить ваш брандмауэр. Если программа вам понравится ее можно купить на официальном сайте или поискать в сети (Пример тут:) . Для того, чтобы проделать такой же фокус с персональным Яндексом или Google Desktop, надо устанавливать прокси сервер.
Поисковик от Google меня сильно удивил и огорчил: установился туда, куда захотел, сам решил, что надо индексировать все мои диски :))), управлять размещение индексных файлов не умеет, управление областями индексирования - абсолютно не вразумительное. Такой "деревянности" я от него не ожидал! Наверное, его интерфейс управления и функциональность проектировал бывший сотрудник службы технической поддержки с нескрываемым презрением в отношении простых американских пользователей :)))). Впрочем, существует версия Google Desktop для предприятий, которая по заверениям разработчиков свободна от этих недостатков.
Не в пример Google Desktop - персональный Яндекс. Конкуренция однако!
{kind=link}
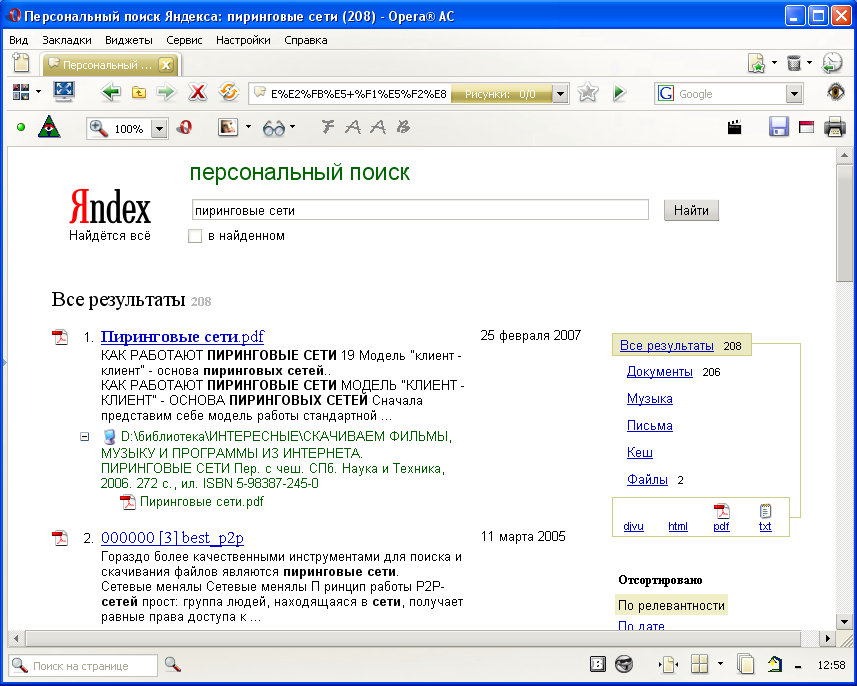
Рис. Пример поиска Персональным Яндексом.(Оптимальный выбор!)
Стабилен, надежен, функционален, бесплатен, полностью управляем. Кроме того, с некоторых пор Яндекс стал бесплатно раздавать Яndex.Server Free Edition для продвинутых и масштабируемых решений. Для полноценного полнотекстового поиска необходимо, что бы все индексируемые документы содержали текстовый слой. К сожалению на практике это не так. В большей степени это относится к файлам djvu формата. Встроенная в Lizardtech Document Express Enterprise система распознавания символов, хоть и поддерживает русский язык, но на практике абсолютна непригодная к использованию. Практически, то же самое можно сказать о OCR встроенной в Adobe Acrobat ХХХ Professional. И только файлы созданные ABBYY FineReader Х.0 Professional Edition имеют качественный текстовый слой. Для того, что бы хоть как-то компенсировать отсутствие текстового слоя в документах воспользуйтесь FindISBN и бесплатной CuneiForm. FindISBN сможет "попросить" CuneiForm распознать необходимое количество страниц из документа. Результат будет сохранен в той же папке, где находится документ, с именем файла документа и добавлением расширения ".txt". Такие файлы легко будут проиндексированы поисковиком. Когда вы после поиска получите ссылку на этот файл открывайте не его, а папку в которой он находится. Там легко найти оригинальный документ без текстового слоя, если конечно вы придерживаетесь модели сортировки "один документ - одна папка". Выбор в качестве OCR CuneiForm продиктован её способностью работать в пакетном режиме. Разработчики ABBYY FineReader, понимая свое монопольное положение лидера рынка, намерено ограничивают функциональность ABBYY FineReader и препятствуют использованию его сторонними разработчиками прикладного ПО. "Бизне$менам" от ABBYY надо хорошо подумать, на что они будут жить, если Яндекс решит взять под свое крыло ставший открытым проект CuneiForm. Тогда функции распознавания изображений и текста будут встроены в персональный поисковик от Яндекса! Кое что подобное уже сделал Google, теперь дело за Яндексом.
Как всегда, выбор поисковика удобного лично вам, только за вами! Однако персональный Яндекс - "лучшее средне - взвешенное решение".
P.S.
После недолгих раздумий, решил добавить возможность использования ABBYY FineReader 8.0 Professional Edition в процессе работы FindISBN. Получение качественных текстовых слоев для dbf и djvu файлов теперь доступно в полностью автоматическом режиме. Для этого написана программа FineReaderToTxt (Подробнее ...), она призвана помочь FineOCR.exe запущенному из командной строки, сохранять результаты распознавания в файл без манипуляций с буфером обмена. В умелых руках FineReaderToTxt может стать ключевым инструментом для организации полнотекстового поиска документов в режиме он-лайн, что-то вроде http://books.google.ru/. В одном из интервью Компьютере ("В России всё ещё выгодно разрабатывать продукты") Давид Ян - основатель компании ABBYY ответил на наши вопросы:
Вопрос: У компании Google есть проект http://books.google.ru/. Участвует ли ABBYY в этом проекте? Если да, то не могли бы вы рассказать об этом подробнее?
Давид Ян: К сожалению, мы связаны соглашением о конфиденциальности и не можем комментировать данный вопрос.
Ау-ууу! Стратеги из Яндекса! Вы все еще спите? Может так случиться, что процесс поиска и поглощения высокопробных знаний у русскоязычной аудитории намертво будет связан с аббревиатурой Google. Не ужели Яндекс устраивает роль локального поисковика второго плана, хорошо ищущего только в периодических он-лайн изданиях, да прайсах сетевых магазинов?
И еще "о птичках":Вопрос: После ухода с рынка OCR компании Cognitive Technologies, ABBYY стала фактически монополистом рынка OCR в России. Как следствие, стремясь извлечь максимум прибыли из своих продуктов, ABBYY из девятой версии FineReader Professional Edition убрала некоторые инструменты, которые присутствовали в версии 8.0. например FineOCR.exe (распознавание из командной строки). Не кажется ли Вам, что урезание функциональности более поздних версий одних и тех же продуктов, это не очень правильный путь, напоминающий методы Microsoft?
Давид Ян: Мы никогда не злоупотребляли доминирующим положением, тем более что на западном рынке мы делим пальму первенства с крупной американской компанией. Мы постоянно находимся в тонусе, в конкурентной борьбе. Что касается российского рынка, основным нашим конкурентом всегда была и сейчас остается пиратская версия FineReader, именно она является доминирующей в России.Ну, ну мы то знаем "откуда ноги растут" :). Некоторые аналитики предсказывают, что с развитием высокоскоростных сетей, широким спектром на рынок выйдут он-лайн сервисы по распознаванию изображений (On-Line OCR). Изображения, полученные как традиционным способом (сканером), так и любым другим устройством, имеющим встроенный цифровой фотоаппарат, с легкостью могут быть распознаны без покупки и установки коробочных версий программ распознавания текста. Т.е. пришел в библиотеку, взял в читальном зале редкую книжку, нашел нужное место и сфотографировал необходимое количество страниц текста. Далее послал эти изображения на такой он-лайн OCR сервис. Результат можно сразу разместить на своём сайте, или получить на коммуникатор обратно виде текста. Возвращаясь домой, можно послушать распознанный текст с помощью синтезаторов речи. Возможно, некоторые сервисы смогут сразу высылать обратно не только файл с распознанным текстом, но и его звуковую транскрипцию. Технологически все программные компоненты уже существуют. Дело за малым - за реализацией. Конец монополии ABBYY? Время покажет!