06.06.12 Обновился
индекс сервера поиска магнет-ссылок
http://dc-poisk.no-ip.org, на сегодня
проиндексировано 835 749 106
имен файлов, у более чем 40000 юзеров Direct Connect сетей. Появилось немного свободного времени :). Теперь с http://dc-poisk.no-ip.org, можно через http ссылки вида http://dc-poisk.no-ip.org/cgi-bin/TestCGI?Download_tth=JDS7OMWBHPSHYS2VBVEUZ6XU3Q4OLBAOH4RVN6Q скачивать файлы, как и у лучшей в рунете библиотеки http://gen.lib.rus.ec/ . Скачивать файлы можно только те, которые есть в моей шаре, а это более 450 000 файлов формата pdf и djvu, объемом около 5Тбайт. У http://gen.lib.rus.ec/ вы можете найти свыше 800 000
книг и журналов, правда в отличие от меня Либген коллекционирует англо
и русскоязычную литературу, я же стараюсь ограничивать себя только
русскоязычной (исключительно из-за ограничений по объему
хранения). Возможность прямой закачки сделал потому, что
теперь благодаря развитию широкополосного интернта в России (спасибо
Путину за web-камеры на выборах:) "средний" тариф за 550 руб. в мес
предполагает скорость отдачи файлов в 40 Мбит/с
и мой пиринговый клиент перестал занимать всю полосу пропускания
исходящего канала. С входящим каналом все еще лучше, ночью около 95Мбит/сек, днем около 40 Мбит/с.
23.01.11 Обновилась
FindISBN (доступна со страницы загрузки).
Добавлена оптимизация извлечеия изображений из pdf файлов и несколько
мелочей.
06.09.10 Обновился индекс сервера
поиска магнет-ссылок
http://dc-poisk.no-ip.org, на сегодня
проиндексировано 350
938 164
имен файлов, у более чем 29000 юзеров Direct Connect сетей.
24.07.10 Временно до 16.08.10
будут не доступны сервисы на http://dc-poisk.no-ip.org
к сожалению, они работают дома, а значит иногда отдолжны отдыхать
вместе с хозяином.
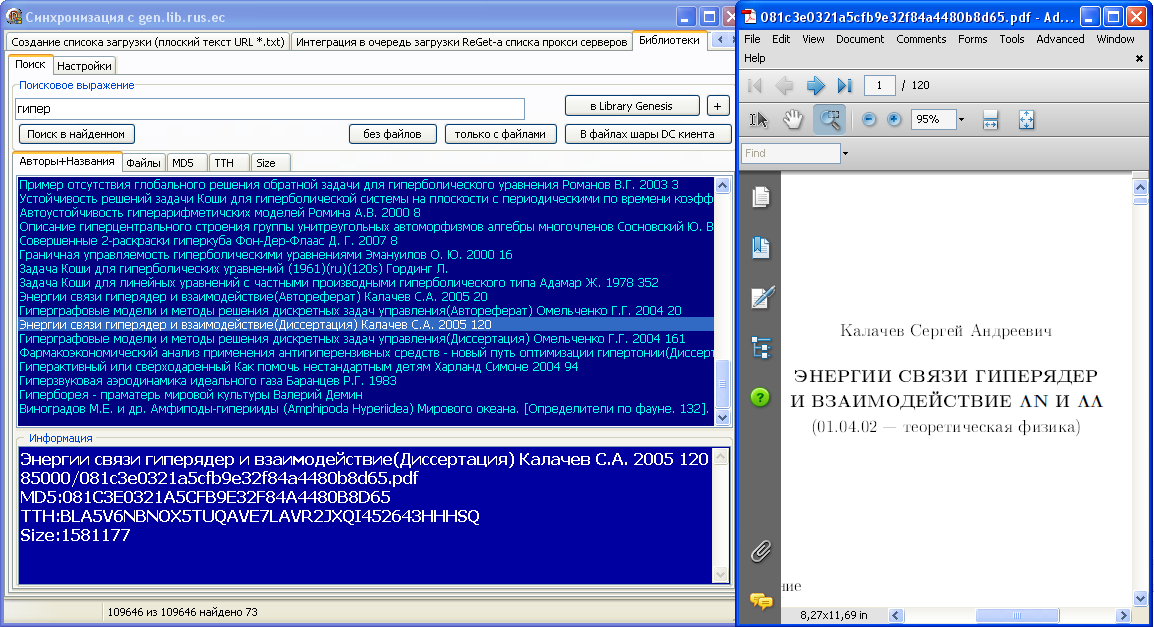
30.09.09 Выложил
новую прогу Sinxro,
быстро ищет любые файлы в вашей "шаре" и открывает их, а так же
позволяет синхронизировать "шару" с большой бибилотекой Library
Genesis. Файлы из библиотеки могут храниться в любом месте
вашей шары, с любым именем.
12.09.09 Выложил
новую версию FindISBN. Появился
новый файл-сателлит *.Error. создается при ошибках извлечения
текстового слоя. Нужен, что бы повторно не пытаться извлекать текстовый
слой.
11.09.09 Выкладываю
новую программу: AddTextAnn
- добавляет текстовые аннотаций книг в
файлы-описатели
(*.SpaceLib.html). AddTextAnn предназначена для создание распределенных
поисковых сервисов, способных искать книги как в пиринговых сетях, так
и на www. http://dc-poisk.no-ip.org:17000/
ищет книги по файлам-описателям созданным с помощью AddTextAnn. Если вы не
готовы скачивать терабайты файлов, а
потом месяцами их индексировать, есть простой способ, сделать поиск
книг прямо
со своего сайта. Надо на страничку добавить маленькую HTML-форму:
<form name="search" method="get"
action="http://dc-poisk.no-ip.org:17000/">
<b>Поиск:</b><br>
<input size="15" name="text" value=""
maxlength="200">
<input type="submit" value=" Найти ">
</form>
Послесловие: "Обзор школьных и студенческих ресурсов
обошелся без электронных библиотек? И это в 2009г.!"
30.08.09 Как всегда новостей
много :)
А. На главной странице дана ссыла на
Очень большую web-библиотеку научно-технической литературы
Library Genesis.
Б. Две,
а иногда и три рабочих станции дома уже больше месяца трудятся в поте
лица, что бы извлечь текстовые аннотации из моих 135679
файлов-книг формата djvu & pdf. Т.к. существующим текстовым
слоям
доверия нет, то из файлов извлекается не текст, а изображение текста,
далее идет процесс оптического распознавания символов.
По окончанию этого процесса, поисковик, заточенный
исключительно под книги (http://dc-poisk.no-ip.org:17000/)
наполнится необходимым содержанием и сможет искать файлы-книги
расшаренные пользователями в пиринговых сетях не только по названию
файлов, но и по их содержанию.
Фундаментальное отличие http://dc-poisk.no-ip.org:17000/
от http://books.google.ru/
состоит в том, что мой поисковик не только поможет понять, какая книга
вам нужна, но и даст ссылки на файлы-книги, которые можно
будет свободно
скачать
на свой ПК и читать без всяких ограничений. Уже сейчас это можно
продемонстрировать на реальном примере. Предположим вы студент и вам
необходимо найти литературу по курсу "Микропроцессорные системы".
Используем ключевые слова, характерные для данной области знаний,
например: +микропроцессор
+память +регистр +команда . Наш пиринговый поисковик на
16000 уже существующих аннотациях к книгам выдаст вам 147 ссылок на файлы-книги, а http://books.google.ru/
всего 320 ссылок. Что же будет, когда
все мои 135000 файлов будут индексированы? 147 и 320 это цифры одного
порядка! Я уж не говорю о том, что все найденные моим тестовым
поисковиком книги есть у меня, и свободно доступны из
пиринговой сети, а у гугл-букс только 0 книг доступно
полностью, и 21
для ограниченного просмотра :).
Теперь оценим релевантность
поиска. Первые пять документов от books.google.ru
1. Referativny? zhurnal, выпуски 10–12 Institut nauchno?
informat?sii (Akademii?a nauk SSSR), VINITI, 1976
2. Путеводитель по компьютеру для школьника Olma Media Group, 2002
3. Radio Ministerstvo svi?a zi SSSR i DOSAAF SSSR, 1984
4. Referativny? zhurnal, выпуск 2 Vses. in-t nauchn. i tekhn.
informasii, 1977
5. Новое в жизни, науке, технике Знание., 1970
Я намеренно
сохранил название
документов в латинице, именно так выдает гугл-букс результаты
поиска в домене .RU!
А теперь от http://dc-poisk.no-ip.org:17000/,
и как говориться "почувствуйте разницу":
1. Григорьев В.Л. Программирование
однокристальных микропроцессоров . 1987г.
2. Управление программным обеспечением Cisco IOS
3. АППАРАТУРА ЦИФРОВЫХ СИГНАЛЬНЫХ ПРОЦЕССОРОВ
Дан Кинг,и др.
4. Могнонов П.Б. Организация микропроцессорных
систем: Учебное пособие. 2003. 355с.
5. Современные микропроцессоры .
2003. - 448 с: ил.
Комментарии
как говорится излишни (но важно помнить, что с появлением новых
аннотаций порядок выдачи документов может меняться!). И дело не в том,
что поисковое ядро от Яндекса
выигрывает у поискового ядра Гугла. Просто мой поисковик использует
"актуальный" контент, сформированный не мифическим дяденькой из USA, а
сообществом активных людей. Такие Русскоговорящие Сканировщики книг
работают не для галочки, а в первую очередь для себя, и щедро делятся
результатами своего труда с нами. Пиринговые сети потому и называют
народными, что они отражают суть процесса формирования и
распространения контента. "Знания
будут свободны!" - вот что пишем мы на наших знаменах.
В новостях
от 02.03.09
я очень не лестно отозвался о Яndex.Server Free Edition. Похоже, в
компании Яндекс оценили свое детище так же и с апреля 2009г. начали
распространять "ентерпрайз" версию своего сервера, ту что раньше
продавали за немыслимые деньги. Yandex_Server-3.10.9-ENT-Windows-i386
сейчас называется Яндекс.Сервер и имеет внушительный список возможностей.
Для меня главным являются:
"Неограниченный
размер и количество индексируемых документов";
"Язык
запросов идентичен
используемому на www.yandex.ru,
включая полную поддержку логических операторов, поиск с расстоянием,
поиск в зонах и атрибутах документа".
Как всегда, не поверив на слово рекламным буклетам, решил
проверить в деле новый продукт. Первая попытка, оказалась неудачна.
Яндекс-сервер при индексации огромного количества файлов (более
9000000) начал безбожно тормозить, проявился так называемый "эффект
замедления индексации". Но судьба свела меня с интересной страничкой руководителя данного
проекта.
После не долгих консультаций, решение было найдено. В конфигурации
сервера нужно было исправить всего один параметр:
PortionDocCount
250 заменяем на
PortionDocCount 100000 и Яндекс-сервер успешно справляется
с задачей индексации 9498246
документов. Почему Яндекс, а не открытый и свободный Сфинкс? Если
образно, то Яндекс-сервер это готовый дом, а Сфинкс это груда кирпичей
из которых домик еще надо построить. Кроме того, если вы
серьезно
занимались поиском документов в сети, вы наверно уже знакомы с языками запросов популярных
поисковиков и вас ничему учить не надо.
Просто берем и используем ваши
знания языка запросов и уникальные
возможности поиска Яндекс-сервера, например:
/N,
в котором N заменяется на число, обозначающее количество слов, которое
может разделять в документе слова запроса;
!
осуществляет поиск без учета морфологии запроса.;
&
и &&
осуществляют поиск слов, встречающихся в одном предложении и на одной
странице соответственно.
31.07.09 Новостей много, просто
писать было некогда :).
А.
Самая важная новость, состоит в том, что найден коллектив "старателей"
делающих с rulib.narod.ru одно и тоже важное дело - распространение
знаний в цифровом виде. Результат их работы, это библиотека-интегратор,
постоянно поглощающая в своих недрах "маленькие" он-лайн библиотеки.
Живет эта "корневая" библиотека здесь: http://gen.lib.rus.ec/
и имя ей "Library Genesis". По содержанию контента позиционирует себя,
как научно-техническая, и профиль в ближайшее время менять не
собирается, в чем её я всецело поддерживаю. http://gen.lib.rus.ec/
корнями своими уходит в один из самых больших библиотечных проектов
Рунета "Либрусек" http://lib.rus.ec/
, его статистика впечатляет: (на сегодня = Всего книг в библиотеке -
112832 томов, 104 гигабайт, Всего представлено авторов - 44384,
Зарегистрированных пользователей - 155742, Посетителей в день - 100K,
Обновлений за последние 30 дней - 3379). В начале лета необходимо было
найти в электронном виде ребенку литературу, заданную для домашнего
чтения на лето. Все нашел на Либрусек-е за 15 минут. Тексты в "Цифре"
дали новое качество, если читать становится лень, горе-ученик быстро
переключается на синтезированную речь и совмещает физическую релаксацию
с поглощением школьной программы. Прогресс однако.
Б.
Проект
http://dc-poisk.no-ip.org жив и на сегодня
проиндексировано 287
981 181
имен файлов, у более чем 16000 юзеров Direct Connect сетей. Можно было
бы и существенно больше, но мой микроскопический канал занят процессом
синхронизации с http://gen.lib.rus.ec/.
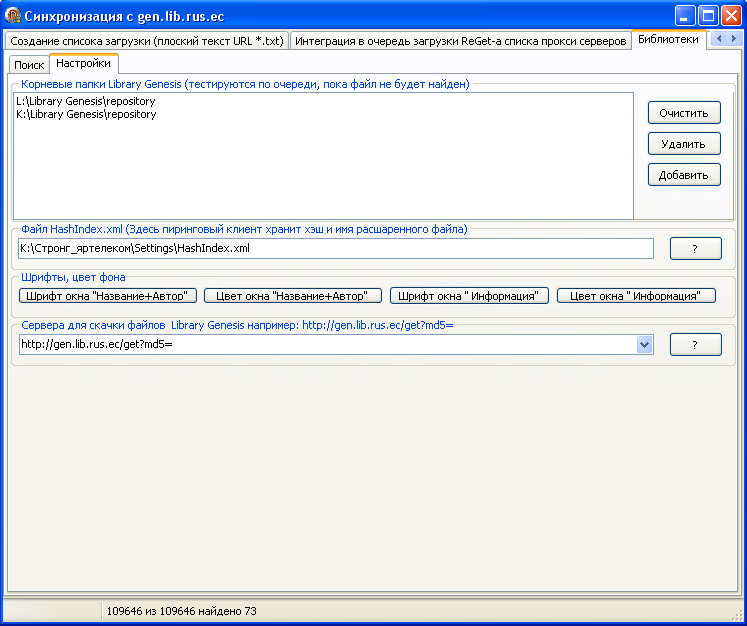
Программа для этого уже написана и всесторонне тестируется (скриншоты: "синхронизация через www
интерфейс библиотеки", "поиск
и тестирование прокси серверов, интеграция прокси в очередь загрузки")
из планов добавить "синхронизация с Library Genesis через пиринговые
сети DC".
В.
Решил, немного описать работу FindISBN.
Программа постоянно дописывается, появляются новые возможности. Их
много и о них лучше читать на
странице программы. Сейчас FindISBN
совместно с (FineReaderToTxt
+ ABBYY FineReader 8.0 Professional Edition) одновременно на 3-ех моих
домашних ПК делают файлы аннотации для примерно 100000 книг и журналов
моей пиринговой библиотеки. Все файлы djvu & pdf
пройдут
через эту процедуру, текстовый слой будет создан принудительно не
взирая на его существование. А поисковик http://dc-poisk.no-ip.org
предстоит научить искать не только в названиях файлов, но и в их
аннотациях. Все это позволит найти книгу в пиринговой сети, даже если,
у её файла не было осмысленного имени пригодного для поиска.
12.03.09 В тестовом тежиме
запущен новый сервер поска
магнет-ссылок на файлы.
Пробуйте здесь http://dc-poisk.no-ip.org . В БД
свыше 179 000 000
магнет-ссылок на файлы доступные в DC сети.
08.03.09 Пока остановился на
связке Sphinx+MySQL, скриншоты
здесь (всего
записей в
таблице более 179 000 000, поиск Sphinx-ом и извлечение
полных
данных о конкретном файле из БД). Интересно время поиска, оно
подозрительно
мало, наверно использованы результаты предыдущего поиска, сохраненные в
кеше.Пределов
масштабируемости на «утилитарном железе» пока
не заметно, посмотрим, что будет дальше.
02.03.09 После
долгих мучений с Яndex.Server Free Edition ему вынесен
приговор: «В топку его!». Максимальное
количество проиндексированных документов со
всеми ухищрениями по
инъекции папок не превысило 6.2 мил. на одну коллекцию. Пробовал я и
Yandex.Server.Pro
версию. Он тоже имеет свои ограничения (на число коллекций), но
главное, это не
бесплатный продукт и его теперь не скачать официально. http://dc-poisk.no-ip.org:17000
на
Яndex.Server Free Edition пока
оставлю, пусть живет, однако в будущем на http://dc-poisk.no-ip.org
будет Апач и sphinx в качестве поисковика, а MySQL или NTFS в качестве источника данных.
К
сожалению MySQL
пока
под вопросом, таблицы (MyISAM)
конечно могут быть большие, но вот эффективно в них индекс строить не
реально.
Это похоже связано с тем, что все ключи пытаются запихнуть в один файл.
Показатели производительности на InnoDB
таблицах еще хуже. Сейчас в тестовой MyISAM таблице около
175 000 000 записей с информацией
о файлах расшаренных пользователями DC сетей и занимает она около 32
Гбайт на диске. Sphinx-у
требуется несколько
часов для построения полнотекстового индекса над полем с названием
файла. Сам поиск
занимает около 0.5 секунды, но все зависит от подсистемы I/O. Индекс
около19 Гбайт
и при таких объемах
в память уже не
помещается. На худой конец, поступлю как Google, и откажусь от СУБД вообще,
под нашу задачу NTFS
подойдет вполне, правда
накладные расходы на хранение данных увеличатся в разы даже с учетом
использования сжатых томов и оптимизации по размеру кластера.
9.01.09 В рамках проекта RuLib запущен
сервер поиска
магнет ссылок http://dc-poisk.no-ip.org:17000.
Его задача показать: как легко
организовать поиск книг и журналов в хабах. Теперь любой энтузиаст без
написания строчки кода может создать базу данных
из миллионов
ссылок на документы. В качестве поисковика пока
выбран бесплатный Яндекс
Яndex.Server Free Edition
, SSearch используется для создания
файлов с магнет-ссылками на файлы. (Обсуждение).
10.11.08 Написана и активно
тестируется новая программа FineReaderToTxt
(скриншот прототипа здесь). Она реализует
пакетное распознавание (Hot Folder for ABBYY® FineReader 8.0
Professional Edition :). Её основная задача помочь FindISBN
надежнее искать ISBN и ISSN в электронных документах (подробнее).
Написана и активно тестируется новая программа - "Поиск
авторского названия книги путем сравнения текстового слоя документа с
библиографическим каталогом" - FindAName, (скриншот прототипа здесь). Проще
говоря, если в тексте есть название книги, оно с помощью FindAName
находится и записывается в файл сателит документа с расширением *.NameBook.
(подробнее).
Обе программы после всесторонней доработки и тестирования будут
выложены для скачивания вместе с исходными кодами.
22.10.08 На
сайте
http://ewrika-ru.narod.ru/ были выложены книги практически не
встречающиеся в сети
27.09.08 Выложил набросок статьи
Оцифровка
бумажных документов.
29.07.08 RuLib начал свою работу!
{kind=link}
{kind=link}