RuLib
FindISBN - программа для полуавтоматического поиска названий книг. Она с помощью сторонних программ извлекает из документов текстовый слой и ищет в нем уникальный код книги - ISBN. Программа только тестируется, полная документация не написана!
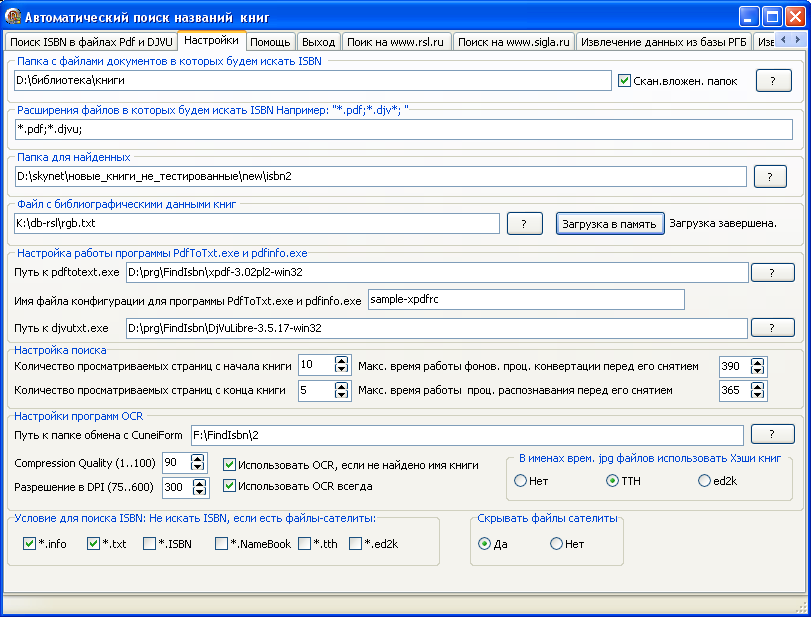
Рис. Настройки программы FindISBN (2) .
Если в файлах-книгах нет текстовых слоев, т.е. они состоят из
изображений страниц, то программа извлекает эти изображения страниц и
просит OCR-программу их распознать. После распознавания в
полученных текстовых слоях FindIsbn без труда уже может искать
уникальный код книги (ISBN). После того как ISBN найден, FindIsbn
обращается к локальной базе данных и по коду ищет полное название
книги. В качестве локальной базы данных используется библиографический
каталог РГБ (http://torrents.ru/forum/viewtopic.php?t=1470611) и БД самого крупного в стране книжного магазина ОЗОН (http://www.ozon.ru/multimedia/yml/partner/div_bs.zip). Уже готовую локальную БД можно скачать здесь (http://narod.ru/disk/10050885000/baza.rar.html).
Это файл "baza.txt", в котором содержится 1358499 записей о
книгах. Его архив "baza.rar" имеет размер 43,515,795 байт. Формат
локальной базы ISBN очень простой:
"Нормализованный-ISBN";"название";"Автор(ы)"; "Год издания"; "Страниц";"ISBN"
9785369002490;Неорганическая химия шпаргалка;;2008;156 с.;978-5-369-00249-0
9785369002742;Психология и педагогика шпаргалка;;2008;126 с.;978-5-369-00274-2
9785753301871;Богомолье : Повести;Иван Шмелев;2008;508, [1] с.;978-5-7533-0187-1
9785867755256;Маша и медведь ;[пересказал В. Мороз] худож. В. Белоусов;2007;[24] с.;978-5-86775-525-6
На
закладках программы: "Извлечение данных из базы РГБ" , "Извлечение
данных из БД Озона" предоставляется возможность самим создать локальную
базу, ведь БД магазина Озон обновляется каждый день. Если в процессе
работы будет найден ISBN, но его не окажется в локальной БД программы,
то на закладках: "Поиск на www.rsl.ru", "Поиск на www.sigla.ru" дается
возможность дополнительного поиска в он-лайн каталогах РГБ и Сиглы.
Особенно хочется отметить поисковые возможности Сиглы. Это HTML шлюз к
крупнейшим библиографическим каталогам мира, работающим по протоколу
(Z39.50) и позволяющий находить названия не только русскоязычных но
иноязычных книг.
Как уже отмечалось ранее, при отсутствии
в файла-книгах текстового слоя, FindIsbn пытается их создать. Но делает
это постранично, и результат сохраняет в файле *.txt, где "*" это имя
файла книги. Например: до обработки был файл:
Fridman.djvu
После работы FindIsbn появятся файлы сателлиты:
Fridman.djvu.info
Fridman.djvu.ISBN
Fridman.djvu.NameBook
Fridman.djvu.tth
Fridman.djvu.txt
Где файлы :
*.info
- хранит информацию о файле-книге, используется для получения
количества страниц в книге для *.djvu файлов и расширенную информацию о
файле для *.pdf.
*.ISBN - хранит найденные ISBN-ы (один ISBN - одна строка)
*.NameBook - хранит найденные библиографические данные (одна запись - однастрока)
*.tth - хранит посчитанный TTH хэш файла-книги
*.txt - хранит извлеченный текстовый слой книги (стр. с начала + стр. с конца)
Так как процесс распознавания очень медленный, то нет необходимости
получать текстовый слой всей книги целиком. Надо лишь распознать
несколько страниц с начала и конца книги. Если вы все же хотите
получить полный текстовый слой, например его в дальнейшем планируется
использовать при организации полнотекстового поиска по содержанию
книги, то полям "Количество просматриваемых страниц с начала книги" и
"Количество просматриваемых страниц с конца книги" надо присвоить
значение 0.
Сама FindIsbn на прямую не обращается к
программам OCR для распознавания извлеченных страниц. Она лишь создает
графический файл страницы в каталоге обмена и ждет его распознавания.
Таким образом, можно использовать различные OCR, которые умеют работать
через каталог обмена. CuneiForm V12 и FineReader в корпоративной
редакции умеют это делать, однако в версии "Professional Edition" такая
возможность не предусмотрена. К сожалению бесплатный CuneiForm не может
конкурировать с FineReader-ом по качеству получаемых текстовых слоев,
увы! Да и ни какая другая OCR программа в мире тоже. На сегодня
(2009г.) для русского языка FineReader абсолютный лидер и монополист,
диктующий свои условия рынку. Для того чтобы использовать уникальные
возможности FineReader-а версии 8.0 была написана маленькая утилита FineReaderToTxt
, аналог Hot Folder for ABBYYR FineReader 8.0 корпоративной редакции.
Её задача добавит возможность "пакетного" распознавания в
распространенную версию FineReader 8.0 Professional Edition.
(Подробнее.. http://spacelib.narod.ru/p_frtotxt.html). FineReaderToTxt
постоянно сканирует "каталог обмена" и как только там появляется
графический файл, отдает приказ FineReader-у на его распознавание, т.е.
превращение в текстовый (*.txt) файл. FindIsbn получив в место файла
изображения страницы его распознанный вариант сразу читает и сохраняет
его содержимое во внутреннем буфере, а сам *.txt страницы удаляет. Как
только все страницы одной книги будут распознаны, в них начинается
поиск уникального кода книги ISBN. Результат поиска сохраняется в файле
сателлите *.ISBN. Из буфера накопленные страницы так же сохранятся в
файле сателлите *.txt. Если в локальной базе по ISBN будет найдено
название или названия книг, то они сохранятся в файл *.NameBook.
Как вы видите, программа FindIsbn написана таким образом, что бы на
каждом этапе работы промежуточные результаты были сохранены
(используется механизм файлов сателлитов). Это необходимо прежде
всего, для того что бы усилить гибкость кода и дать возможность другим
программистам не "заморачиваясь" с извлечением текстовых слоев самим
попытаться искать ISBN-ны и соответственно названия книг, а возможно и
УДК с ББК. Ведь все необходимые данные сохранены в файловой системе в
виде файлов сателлитов.
Если вы расшариваете свои книги в
пиринговой сети и их "очень много", то ваш файл-лист может стать "очень
большим", что "не хорошо". Избежать этого можно выбрав в наборе
радио кнопок "Скрывать файлы сателлиты" кнопку "Да". У всех
файлов сателлитов будет установлен атрибут "скрытый" и пиринговый
клиент их расшаривать не будет, если конечно вы его об этом не
попросите. Правда в некоторых случаях, файлы сателлиты могут быль
полезны человеку, который не уверен, стоит ли скачивать у вас
конкретную книгу большого размера. А так, скачав файлы сателлиты,
имеющие по нынешним временам микроскопический размер, он сможет
составить свое представление о конкретной книге без ее фактического
скачивания.
Кроме основной функции: поиск названий книги эта
программа может стать создателем файлов аннотаций книг. Для этого
предусмотрен набор радио кнопок "В именах врем. jpg файлов использовать
Хэши книг". Если вы выберите один из видов кешей, то каждый графический
файл страницы, который предназначен для распознавания связкой
(FineReaderToTxt + ABBYY FineReader 8.0 Professional Edition) будет
иметь уникальное имя состоящее из хэша книги и номера страницы.
Далее в FineReaderToTxt надо будет выбрать "Сохранять результат
распоз. в виде *.htm файлов и файлов изобр. к ним" и желательно
"Создавать подпапки (2 первых символа от имени)" с "Не сохранять
результат распоз. в виде *.htm файлов и файлов изобр. к ним, если
страница ранее была распознана". После этого FineReaderToTxt
начнет не только преобразовывать исходное изображение в текст, но
и сохранять результаты распознавания в виде *.htm файлов в папке
название которой будет установлено в строке ввода: "Папка, где будут
создаваться новые папки с результатом распознавания в виде *.htm файлов
и файлов изображений к ним". Такие *.htm файлы сразу готовы для
размещения на вашем сайте и индексации их поисковыми машинами.
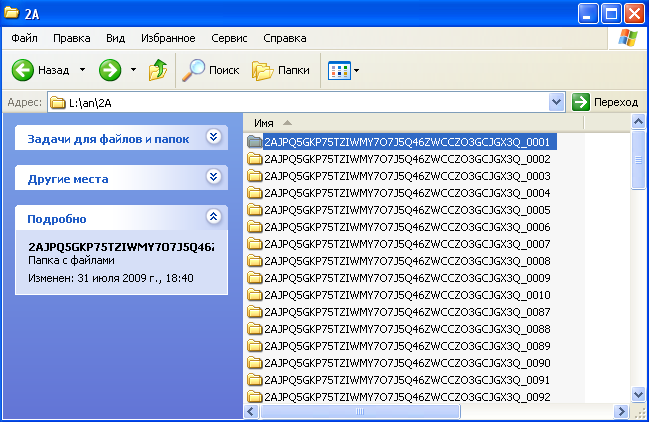
Папка с каталогами-хэшами книг - в каждой папке одна страница книги.
Содержимое папки - одной страницы книги.
Если при создании книги автор использовал простое форматирование
текста, то результат в *.htm-ках после автоматического распознавания
будет вполне приемлемым,
иначе в случае сложно отформатированного текста, FineReader будет
бессилен. Он же не человек и не обладает искусственным разумом, а
следовательно, от него что то сверх естественного ждать не стоит
("каша" на странице обеспечена).
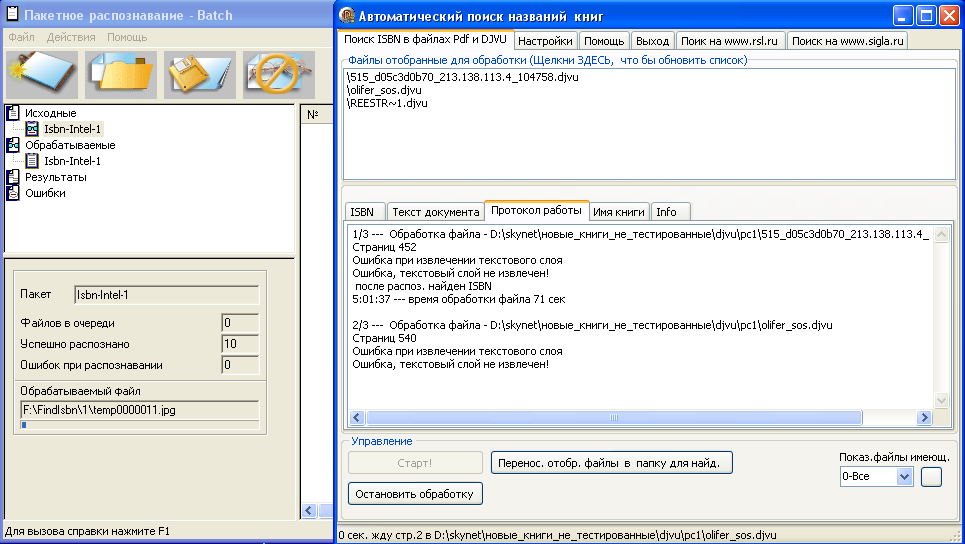
Рис. Работа программы FindISBN по поиску названий книг совместно с CuneiForm.
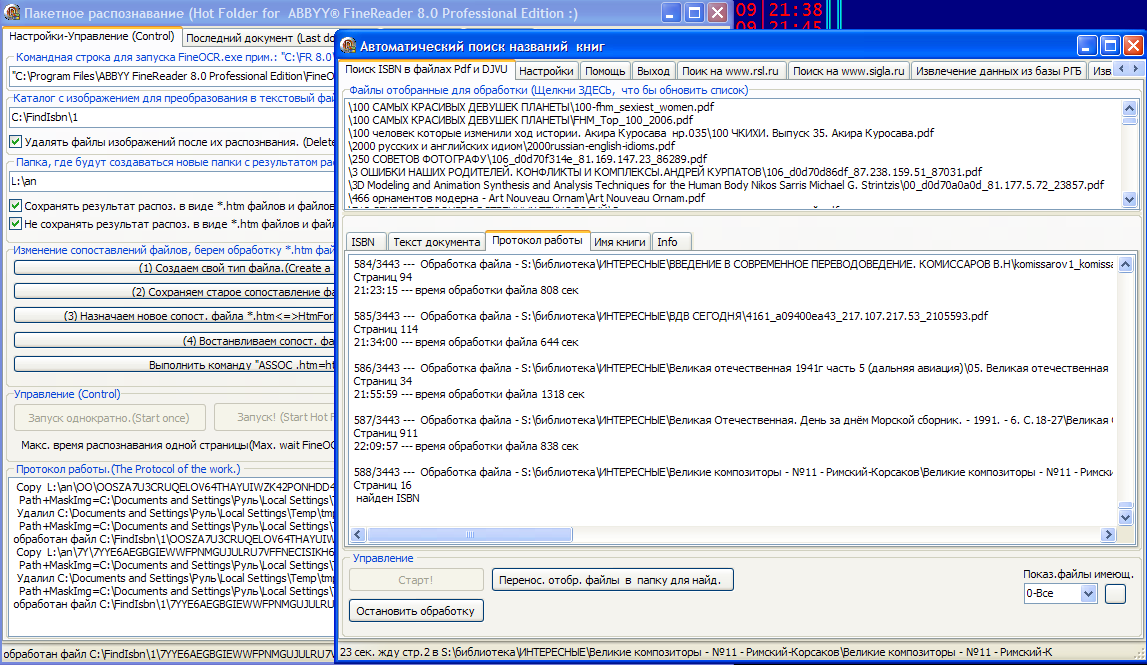
Рис. Работа программы FindISBN по поиску названий книг совместно с (FineReaderToTxt + ABBYY FineReader 8.0 Professional Edition)
После извлечения ISBN перед его поиском в онлайновых каталогах, рекомендую "пробежаться" по значениям ISBN и руками их подкорректировать если это необходимо. Делайте это на закладке "Поиск ISBN в файлах Pdf и DJVU"-"ISBN" (F2-сохранить текст, DOWN +Ctrl перейти к редактированию следующего ISBN, UP+Ctrl перейти к редактированию предыдущего ISBN )
(Внимание ! для корректной работы FindISBN по минимуму необходима: База названий книг Озона - см. Загрузка, CuneiForm V12 (или (FineReaderToTxt + ABBYY FineReader 8.0 Professional Edition)), правка путей в sample-xpdfrc, замена следующих строк на свои:
http://aleph.rsl.ru/F/PQ86RJUK7H1667CSFG8K9MPF5D9S4JGXCEY1U16IEJX4BYN3HH-00314?func=find-b&request=%ISBN%&find_code=WIB&adjacent=N&x=25&y=12
Заходите сюда: Единый электронный каталог (ЭК) РГБ дале выбираете пункт "Простой поиск" и попадаете в форму поиска. В строке браузера появляется что типа http://aleph.rsl.ru/F/IUG2T495IJ7IBS7BMMGDM5VSPBSI98FMLACJDBAQ97LMIPYFGT-03726?func=file&file_name=find-b --- у вас будет другое!!! Все цифры и буквы от начала строки до "?func...." перенесите в программу в место старых значений. Т.е. вы меняете сеансовый хэш!Сигла должна работать без правки этой строки в программе, однако это не тестировалось!
http://www.sigla.ru/table.jsp?f=7&t=3&v0=%ISBN%&f=1003&t=....обрезано... )После обработки всех книг отберите только те, что имеют названия. Это делается с помощью фильтра на главной странице. Далее выберете каталог для найденных книг и жмите кнопку переноса "Перенос отобранных файлов в папку для найденных". Отобранные документы переименовывайте с помощью с помощью AllDocView.
Мне удалось протестировать FindISBN на 4-ех процессорном сервере (Intel Xeon) с RAID массивом из SCSI дисков. Цель: извлечение текстового слоя или его создание для организации полноценного полнотекстового поиска. Было обработано более 40000 документов. К сожалению сторонние программы, используемые FindISBN, периодически встречаются с документами, которые не могут корректно обработать и зависают. Для продолжения их работы необходимо вмешательство человека. Индексации длилась более недели (вместе с временем простоя из-за зависания сторонних программ) и это при условии распознавания не более 10 страниц из каждого документа. Если скорость обработки еще можно повысить (есть резерв), то качество распознавания обеспечиваемое CuneiForm V12 удручающе (по сравнению с ABBYY FineReader 8.0 Professional Edition). И все таки, у CuneiForm V12, как мне кажется перспектива есть! Исходные коды открыты, потребность на рынке в прикладных OCR есть. На простых сканах страниц, с высоким разрешением, без графики и без подстилающего фона под текстом, работа CuneiForm V12 вполне приемлема. Это значит, что добавив "немного" предобработки для сканов, можно добиться существенного прибавления качества распознавания текста.
Программа написана на паскале в среде Delphi и распространяется с исходными кодами. Удачи!